The (true) cost of data daily updates


What is the perfect amount of information to be used in Master Data Management? Is more always better? When should you take an information into account and what is the effect of extending the information scope to a broader set of information for each business partner?
At CDQ, we help our clients to integrate and digest the information from various sources. Our clients use CDQ capabilities to connect, download and receive updates from original registries, open sources, commercial data providers and from our Data Sharing Community. All of these data are harmonized into the CDQ data model to make the heterogeneous data digestible for standardized processes.
So, in a nutshell: We are helping our customers to make use of all sorts of Business Partner Master data coming from many different sources.
During master data integration projects, we reach the following situation quite often: What data sources should come into play? What data should be used for the Master Data Governance Process?
Business Partner Master Data: Easy address data or a broad set of information?
There is no easy answer and none that fits all. Some want rudimentary data but want it as fresh as possible, while others prefer a broad set of information updated on a less frequent level. Some want event-driven updates, some do full updates in defined intervals and again others update chosen sub-portfolios of their Business Partners in infrequent schedules. Behind these decisions is the question how much the Master Data organization can handle: Thin data has less updates while wide definitions will receive more. This is no surprise - if you subscribe to multiple newsletters, it will also be more likely to receive more updates.
7% of Master Data Records change each day
We have been following our clients introducing daily updates from large international sources. These sources beckon with the widest data elements and the most recent information. Of course, you want to stay updated. But can your organization handle the consequences?
Let’s make an example:
A Business Partner Portfolio of 300.000 customers and vendors receives roughly 20.000 updates per day, that’s about 7 percent. That is a lot of information to cope with: In a fully manual approval process, let’s assume that you need 4 minutes for opening, checking, correcting and approving a record. Then you would need about 160 working days to check the incoming updates of a single day.
It is hard to imagine that any organization keeps that kind of workforce in the Master Data Governance process, especially because new updates will arrive the next day and everything starts over.
Underneath the hood of Master Data changes
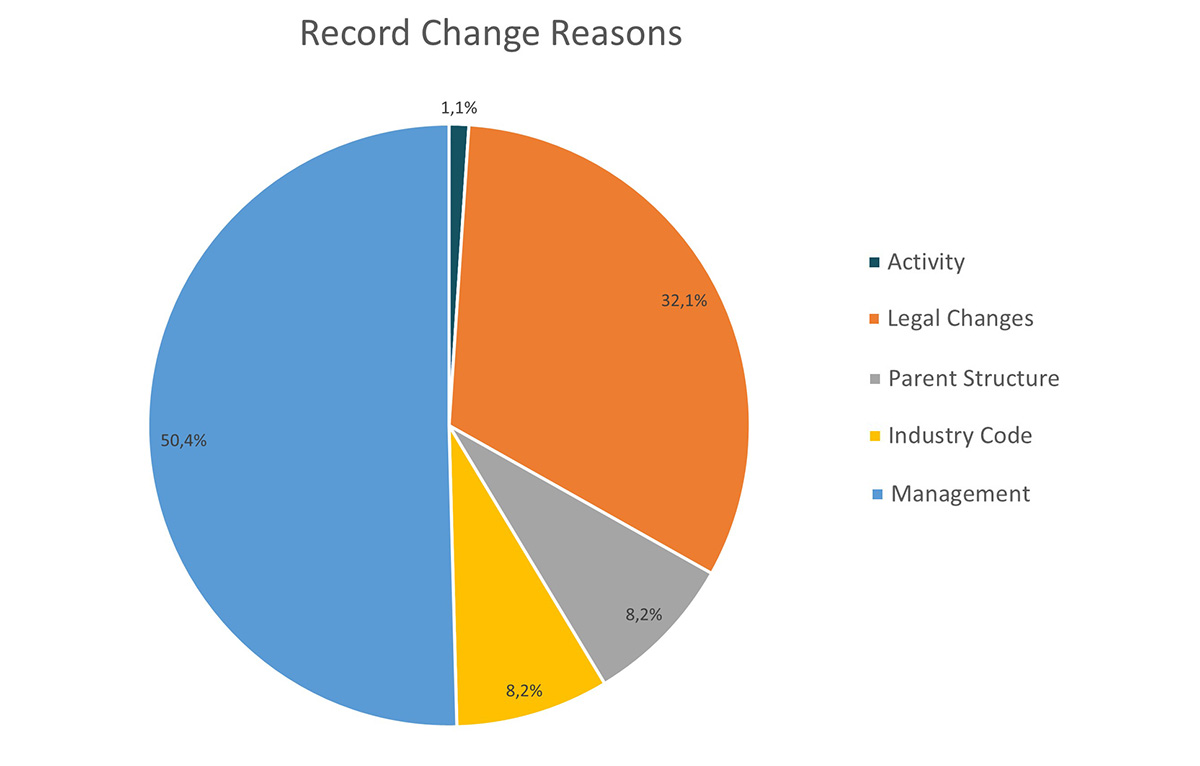
We have analyzed the incoming updates and categorized the changes into following groups:
- Updates on the activity state (e.g. the closure of a company)
- Updates on the legal state (e.g. name changes, legal form changes, changed addresses etc.)
- Updates in the parent structure (e.g. a mother company has changed or the company has been sold)
- Updates of the industry classifications (e.g. a company is doing business in a different industry sector than before)
- Updates in the management
- Irrelevant updates that cannot be classified by the above
It turns out that over half of our 20.000 updates (53%) belong to the last group of irrelevant updates. Simply by filtering, we cut down the relevant updates from 20.000 down to roughly 9300.
Depending on your Master Data Governance procedures, the relevance of delivered updates can be further narrowed down:
Only use the data really needed to the data governance process
CDQ services map data elements from open and commercial sources into a shared data model. This harmonizes the data to a common denominator: data can be digested independent from which source it comes from. All incoming Master Data is mapped into the harmonized CDQ data model minimizing the effort needed to check on changes that cannot be covered by all your data sources.
The CDQ data model gives a common ground and makes Master Data update processing more efficient. The result is that the majority of non-relevant changes mapped to a common data model make it beyond this point.
Some numbers on our example:
We have now filtered the daily updates onto the relevant fields and mapped them into the CDQ data model. In our case, we focused on any legal changes (change in address, legal form and other relevant fields) and a change of the company status (indicating company closures). Out of the 20.000 updates, only about 3.800 remain after this exercise – that is an impressive 81% less . But given the 4 minutes for every manual approval, it would still take you an estimated 32 days to acknowledge the changes manually. That is still far too much for an average sized-master data department to cope with.
Filtering the data to the relevant changes only does not win the game. We need more intelligence to be ingested into the process.
Adding the Governance into Master Data Management
We need to look deeper into the incoming updates. There will probably be many updates that can be accepted automatically, while edge-cases are to be checked by a person: Let the machine to the mass-work, but only accept the acceptable.
CDQ clients have access to an automated analysis of the incoming updates, based on more than 2100 business rules created by the expert knowledge of the CDQ Data Sharing Community. These rules do a 360-degree-check on the incoming master data on various dimensions of data quality:
• Completeness: Rules that ensure all the required fields or data elements are present in the dataset.
• Validity: These rules verify if the data aligns with specific data types, formats, or value ranges. For instance, it examines whether postal codes or tax-IDs are in accordance with local standards
• Consistency: Checks whether the data is consistent across multiple sources or datasets. For example, if a customer's address is stored in two different databases, both records should have the same address.
• Accuracy: Guaranteeing the data is free from errors, inaccuracies, or inconsistencies.
• Integrity: Data should be like a good relationship - correct, reliable, and relevant over time. Rules keep it real, keep it honest, and keep it relevant.
• Timeliness: Rules assure that the data is up-to-date and suitable for its intended use.
• Uniqueness: To make sure each record in the dataset is unique and has no duplicates.
• Relevance: This rule ensures that the data is relevant and useful for the intended purpose or application.
These rules can be applied to various types of data, such as customer data, product data, financial data, and more. By applying these rules, organizations can improve the quality of their data and make more informed business decisions. They contain country-specific checks, e.g. if abbreviations and legal forms are correctly spelled, if the postal code fits to the companies address, if the given street exists in the given town, etc.
Update Classification created by innovative leaders in Master Data Governance
(aka CDQ Data Sharing Community)
The incoming updates are automatically checked and categorized into update classifications in order to drive automation. Each change is notified on field level and summarized on record level. Each classification level can be picked up by your approval processes in order to extend the automation on content level. In our example, we decided to auto-approve all records that either had no defect or issues considered minimal (“Info”) while all findings in the content of the update that was considered more significant would need to be put into a more detailed checking process.
The results of the content check by the CDQ Data Quality Rules can be seen in the following graphs:
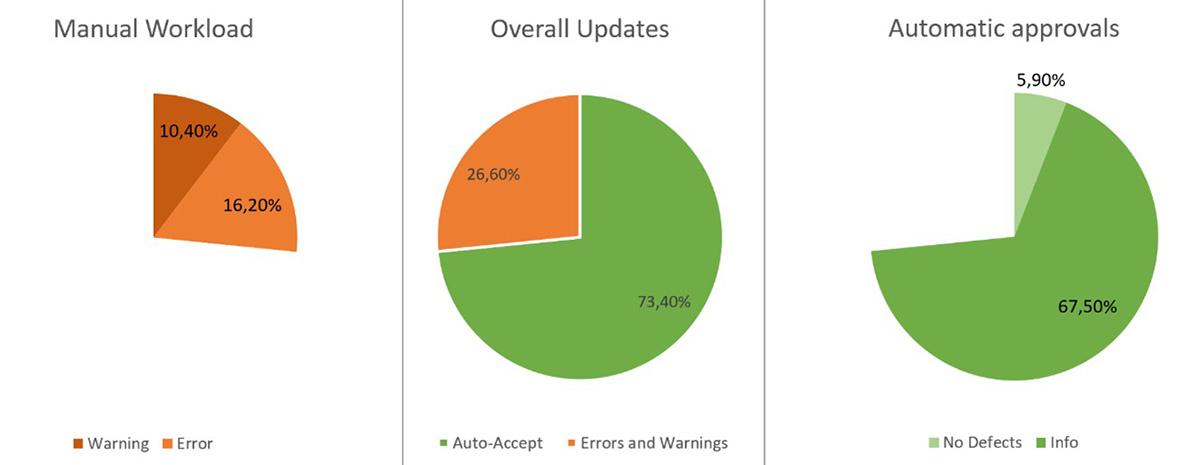
After checking the changes, it turns out that almost three quarters of the updates on legal changes and company closures can be auto-accepted. That reduces the manual effort to 26.6% of the original numbers.
Translated into workload for the daily updating of the original 20.000 cases down to 2500 cases. That means that we have automated 88% of the incoming updates leaving the Master Data departments with only 12% of the original workload. If we consider errors only, this would only be 7.6% of the original work. So, content change classification works and helps you in focusing master data managers onto the important changes. In our clients-situation, warnings will be put into a semi-automated workflow, while only the content errors are placed into a manual review.
The application the CDQ-Sharing-Community-driven update classifications makes the difference:
With the acceptance-rules set to automatically allow all minor changes, only 1.500 cases out of the originally 20.000 daily remain for manual review.

In terms of automation, this means that a 300.000-Business Partner Portfolio can be administered a significantly smaller team with daily updates in place. Compared to the manual effort of approving the daily updates, the intelligence inside the CDQ mechanisms have reduced the workload by 88%.
But is this the end of a discussion? Can updates be further automated? Stay tuned for more!
Conclusion:
- A constant stream of updates can be a challenge even for large master data organization
- The approval-process needs to be streamlined to avoid manual workload
- CDQ helps with smart, intelligent, integrated and customizable solutions on getting the data for the First Time Right and to make the data Stay Clean.




Get our e-mail!
Related blogs

Turning compliance challenges into manageable workflows
The world of compliance is a fast-moving, complex landscape, and for many teams, staying ahead of regulations (e.g. AMLD5) feels like an endless game of catch…

Master Data Management meets AI: work smarter, not harder
Let's be honest, master data management (MDM) often feels like a Sisyphean task. Wrangling inconsistent data, battling data decay, and striving for a single…

How AI and MDM work together to drive business success
In today's fast-paced world, Artificial Intelligence (AI) is becoming a must-have for making smart decisions, automating tasks, and discovering hidden insights.…